Good Thinking
Sometimes there are things that defy easy categorization, but that are simply good ideas. Here is where you'll find them.
Latest News
-

$300,000 robotic micro-factories pump out custom-designed homes
April 20, 2024Construction is the world’s largest industry, contributing 13% of global GDP. It is also the most inefficient, least digitised and most polluting industry. Now AUAR has begun rolling out an ingenious end-to-end solution based on its micro-factory. -
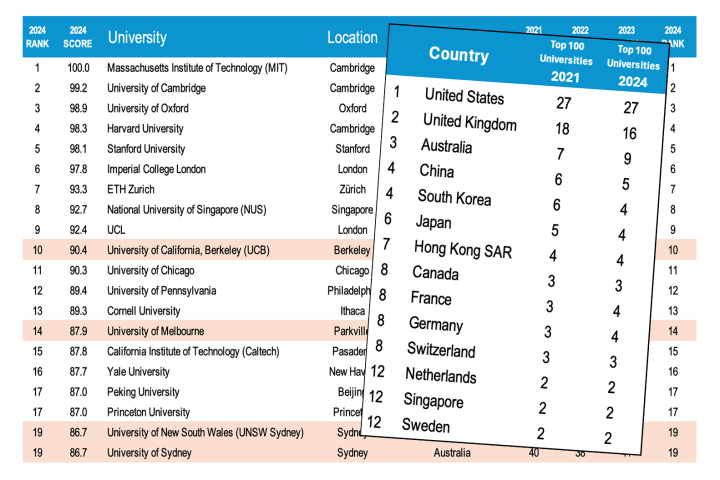
Movement at the top in 2024 World University Rankings
April 13, 2024The 2024 QS World University Rankings were released this week, and with three new key metrics added to the scoring process, several universities have rocketed to the international forefront, while traditional icons are being pushed below the fold. -

Personal 'invisibility shield' goes on sale, starting under $70
March 27, 2024If you've ever wished that you could turn invisible, here's your chance. A consumer "invisibility shield" has just hit Kickstarter, and it could be yours for as little as £54 (about US$68). -

Video: Heat-gun-toting robot could create bespoke clothing on the cheap
March 09, 2024Custom-fit clothing is usually quite expensive, but perhaps it doesn't have to be. MIT's 4D Knit Dress is an example of a new type of clothing that a robot could selectively shrink to fit the wearer, perhaps right in the store. -

BMW is building high-tech footwear for the German bobsleigh team
March 07, 2024There's only a few seconds of running in a bobsleigh heat, but one slip can skittle the whole team. Seeing the need for high-performance ice sport footwear, BMW has jumped in to build custom, 3D-printed traction aids for the 2025 Winter Olympics. -

Video: Eco-friendlier offshore fish farm sinks to ride out storms
March 07, 2024A new type of storm-resistant fish farm could make aquaculture operations more eco-friendly. The submersible structure is designed to stay in the deep waters of the open ocean, where it should have less environmental impact than shore-adjacent pens. -

MiniTouch lets existing prosthetic hands relay a sense of temperature
February 12, 2024There are already a number of experimental prosthetic hands that provide users with the tactile sensation of touching an object. The MiniTouch system takes things further, as it allows users to sense the temperature of items that they're touching. -

App uses a smartphone's camera to guide the blind to bus stops
January 30, 2024While there are already apps that guide blind users to a bus stop's GPS coordinates, those people may unknowingly end up standing too far away from the actual stop. A new app addresses that shortcoming, by letting the phone's camera in on the act. -

Facial recognition app helps scientists identify rabies-vaccinated dogs
January 25, 2024In regions where dogs often run loose, don't wear tags and aren't chipped, it can be hard for authorities to keep track of which ones have been vaccinated against rabies. A new app could help, by identifying dogs via facial recognition technology. -

Simple cellulose filter thoroughly purifies syringe-injected water
January 24, 2024While we've seen quite a few filtration systems for making polluted water drinkable, many are quite complex, or utilize costly materials. By contrast, an experimental new setup simply requires users to inject dirty water through a layer of cellulose. -

Attention, multitaskers – scientists create a belly-controlled third arm
January 22, 2024There have doubtless been times when you've had both hands full, and wished that you had a third arm. Well, scientists have discovered that a robotic third arm can in fact be quite easily controlled via movements of the diaphragm muscle. -

Hedgehog "crash test dummy" may save the critters from being robo-mowed
January 16, 2024It's a sad and gruesome fact that robotic lawnmowers sometimes run over hedgehogs, maiming and even killing them. That's why scientists have recently developed a rubber hedgehog stand-in, for safety-testing such mowers. -

Kim-e electric wheelchair gets users standing and rolling
January 15, 2024For many wheelchair users, one of the biggest problems with using a chair is not being able to stand as tall as other people. The Kim-e wheelchair was designed with that fact in mind, as it raises its user to an upright stance in just a few seconds. -

Study reveals which Zoom background items make you look more competent
January 10, 2024Before you hop on your next Zoom call, you might want to tailor your background in a very particular way, says a new study. Doing so could make everyone else on the call perceive you as being more competent – whether or not you really are. -

Assistive "anti-freeze" exoskeleton keeps Parkinson's patients walking
January 08, 2024People with Parkinson's disease often develop a problem known as "gait freeze," in which their legs simply stop stepping forward as they're walking. A new exoskeleton, however, has proven to be very effective at keeping such individuals' legs going.
Load More